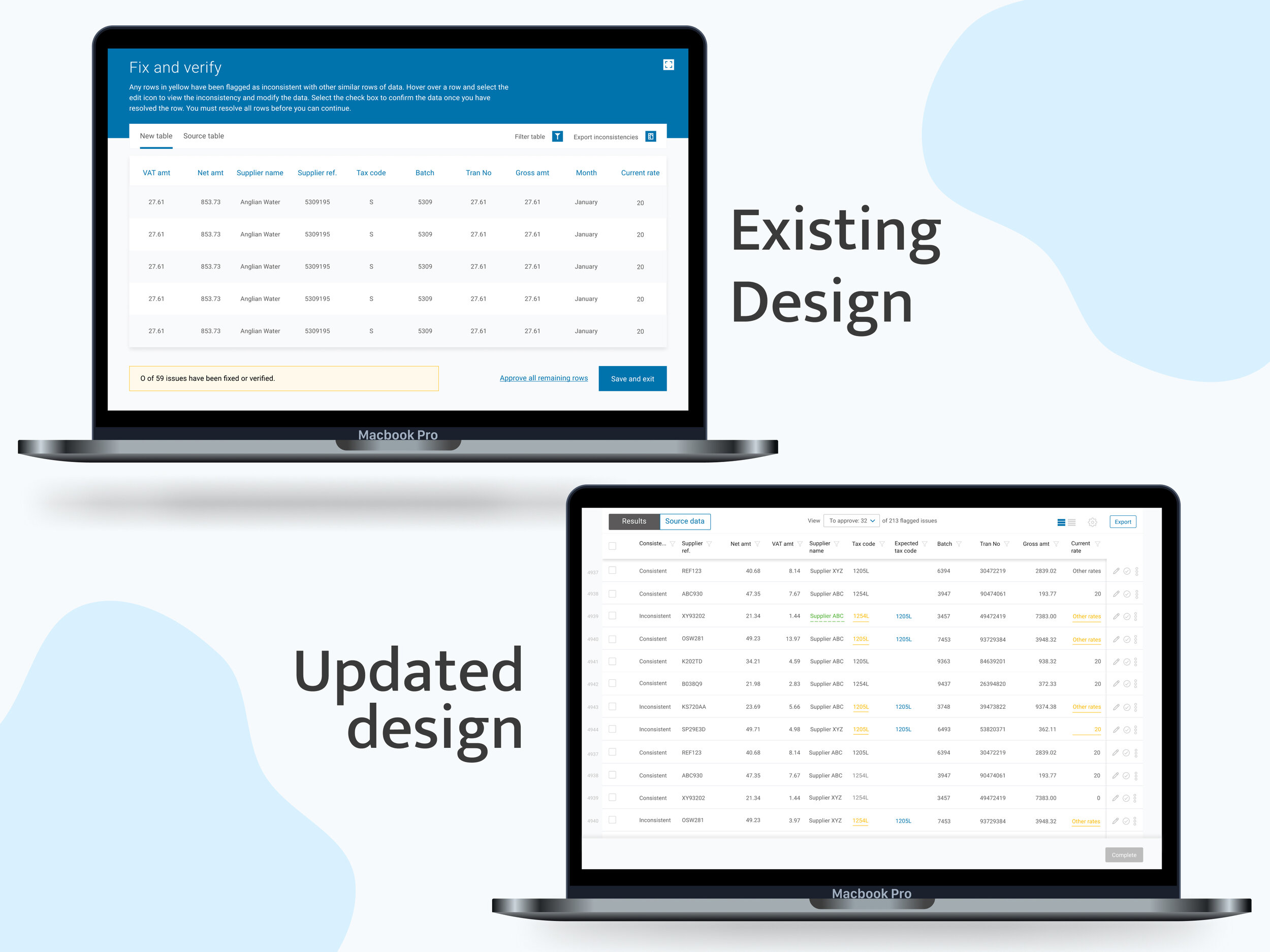
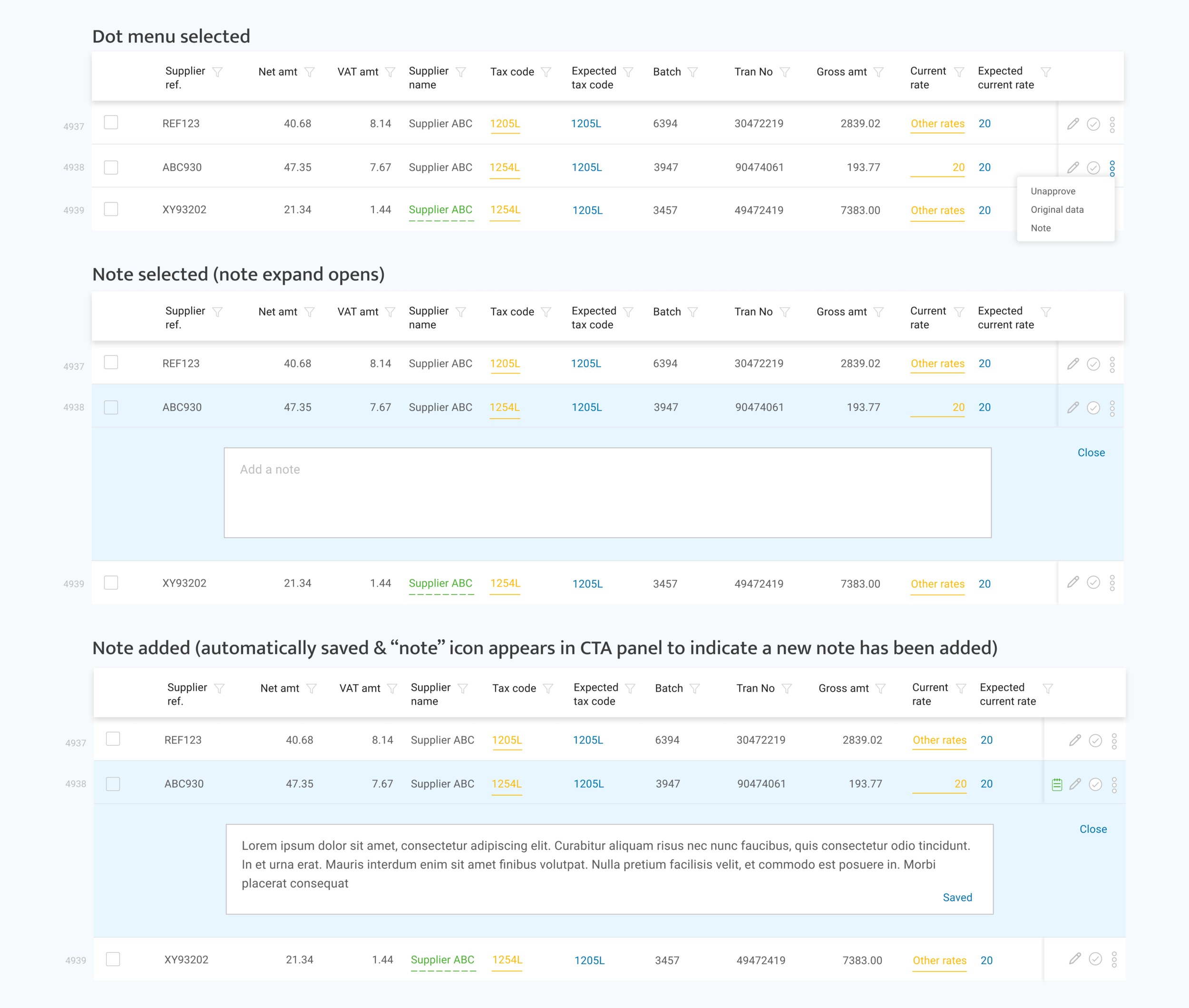
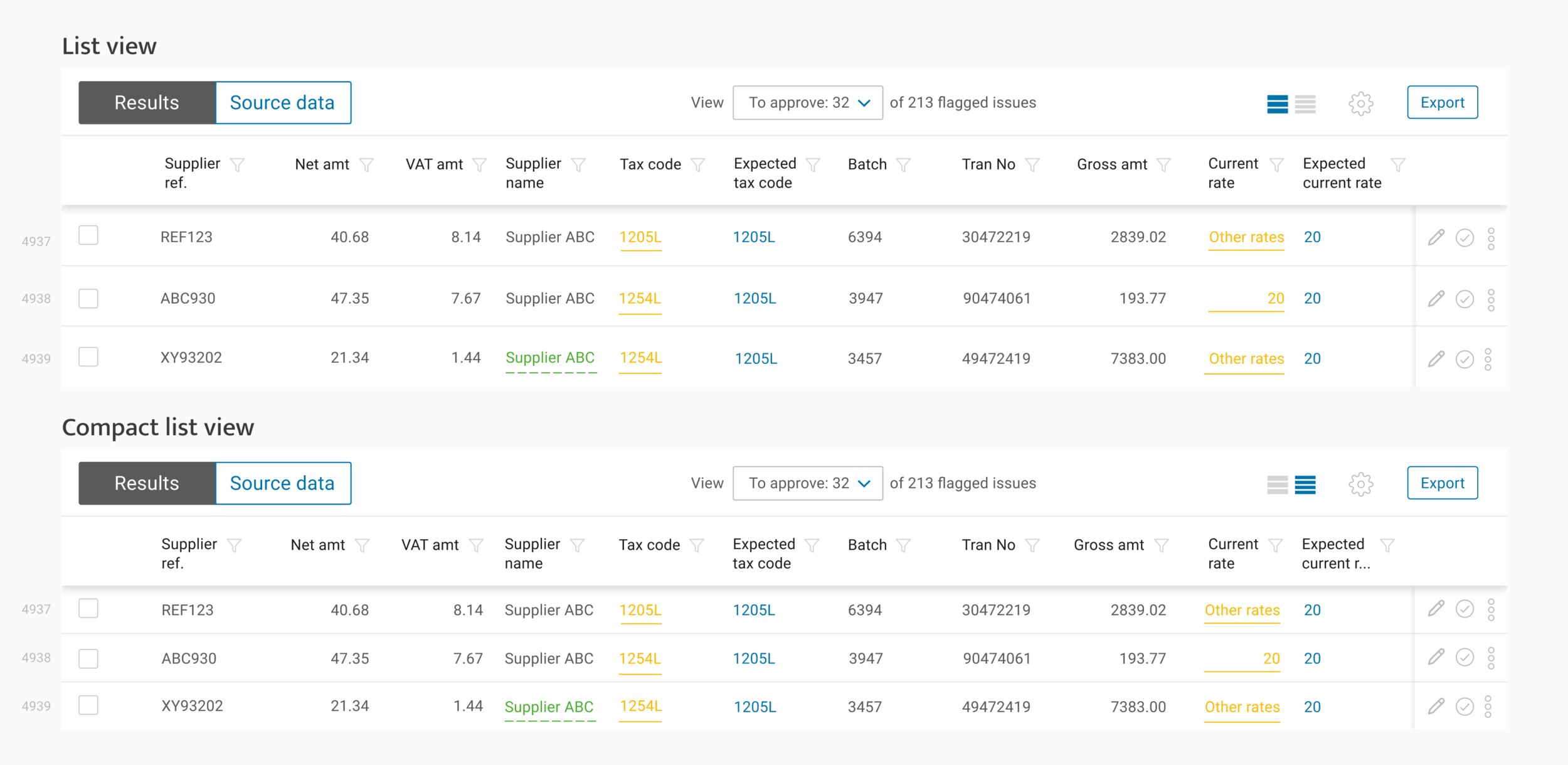
Flagged, edited and flagged & edited cells
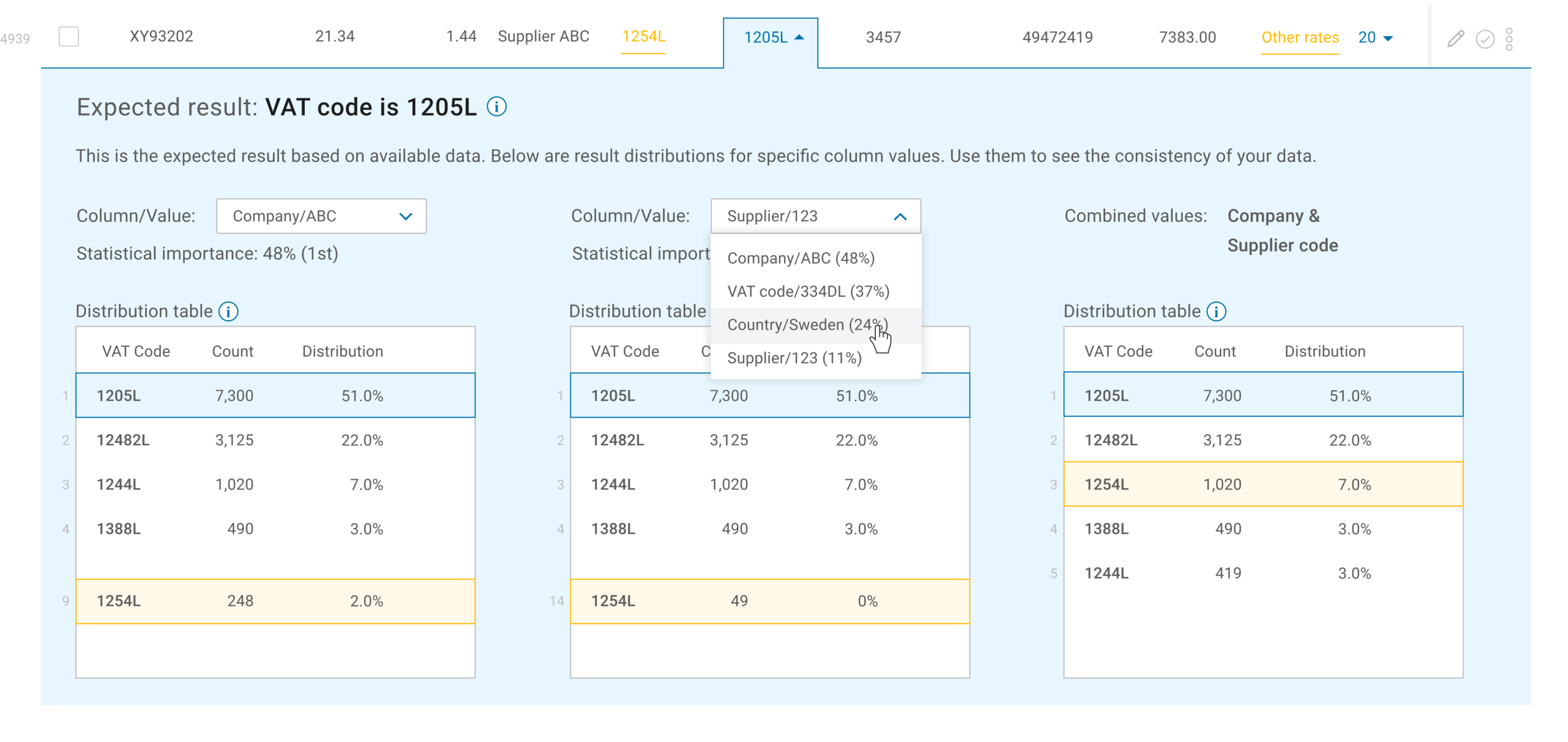
The analysis expand can be opened in any row that has an “expected result”. The purpose of this expand is to explain to the user why the machine learning believes a specific column value is expected to be a different value (this could be based off of previous data uploads).